


Sep 24, 2025
Recently, Dr. Chengbin Hou’s team from the School of Computing and Artificial Intelligence at Fuyao University of Science and Technology in Fuzhou, China, in collaboration with Tsinghua University and Southern University of Science and Technology, reported new progress in efficient LLM prompt compression. Their paper, “Parse Trees Guided LLM Prompt Compression,” was published in IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) in 2026.

As large language models such as ChatGPT and DeepSeek continue to demonstrate outstanding performance across many tasks, the prompt design has become increasingly critical. However, long prompts can substantially increase computational cost and may exceed model input length limits. Existing prompt compression methods also face issues such as hallucinations, insufficient use of linguistic structure, and low computational efficiency. To address these challenges, the research team proposed PartPrompt, a prompt compression method based on parse trees. This is the first approach to incorporate linguistic rules and global text structure into prompt compression, significantly improving compression efficiency while preserving semantic integrity and enhancing coherence and readability.
Specifically, this work employs parse trees to construct sentence-level structures, and introduces the global hierarchical tree to analyze and integrate sentences according to textual characteristics. A node value adjustment algorithm is then designed to simulate human writing logic. This work further employs local information entropy approximation to reduce computational complexity. On this basis, the prompt compression problem is reformulated as the tree pruning optimization problem, and an efficient algorithm is accordingly developed to solve it.
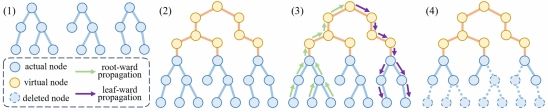
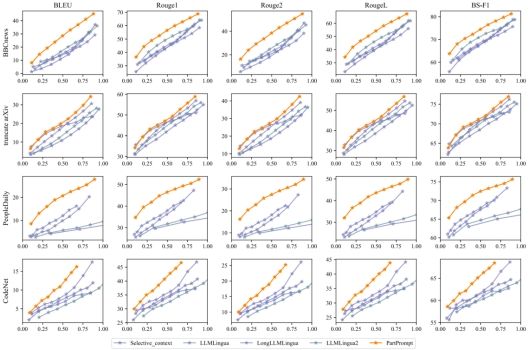

The research team conducted comprehensive experiments over eight datasets of different types, including English, Chinese, code, and long text. Results show that PartPrompt consistently outperforms existing mainstream methods such as Selective Context, LLMLingua, and LLMLingua2 across these settings. In scenarios with extremely long prompts exceeding 6000 tokens, PartPrompt remains effective, while existing methods cannot handle such cases well. The compressed prompts show strong semantic coherence and structural completeness, and significantly improve downstream task performance in summarization, question answering, and mathematical reasoning. The method also provides high computational efficiency with lower complexity than other methods, making it more practical for real-world applications. To support further advances in this area, the team has publicly released both the curated datasets and the source code.
Paper link: https://ieeexplore.ieee.org/document/11164467
Preprint: https://arxiv.org/abs/2409.15395

No. 104, Zhihui Avenue, Fuzhou High-tech Industrial Development Zone, Fujian Province

University Office: 0591-62180087 Undergraduate Admissions Office: 0591-62180153
office@fyust.edu.cn






© 2025 FYUST 104 Zhihui Avenue, High-Tech Zone, Fuzhou, Fujian, China 350109 Email: office@fyust.edu.cn Tel: +86 (0)591-62180087


